The ZenHire resume parsing API turns a raw PDF or DOCX CV into clean JSON (work experience, education, skills, and contact details) from one REST call, at 97% field-extraction accuracy and bulk volumes of 1,000+ resumes per role. It is one of the ZenHire hiring intelligence APIs built to feed structured data into any recruitment stack.
{
"contact": {
"name": "candidate",
"email": "c@example.com",
"phone": "+1-000-000-0000"
},
"experience": [
{
"title": "Support Team Lead",
"company": "Contact Center Co.",
"years": 4.0
}
],
"education": [
{ "degree": "BSc", "field": "Business" }
],
"skills": ["CRM", "SLA reporting", "coaching"],
"confidence": 0.97
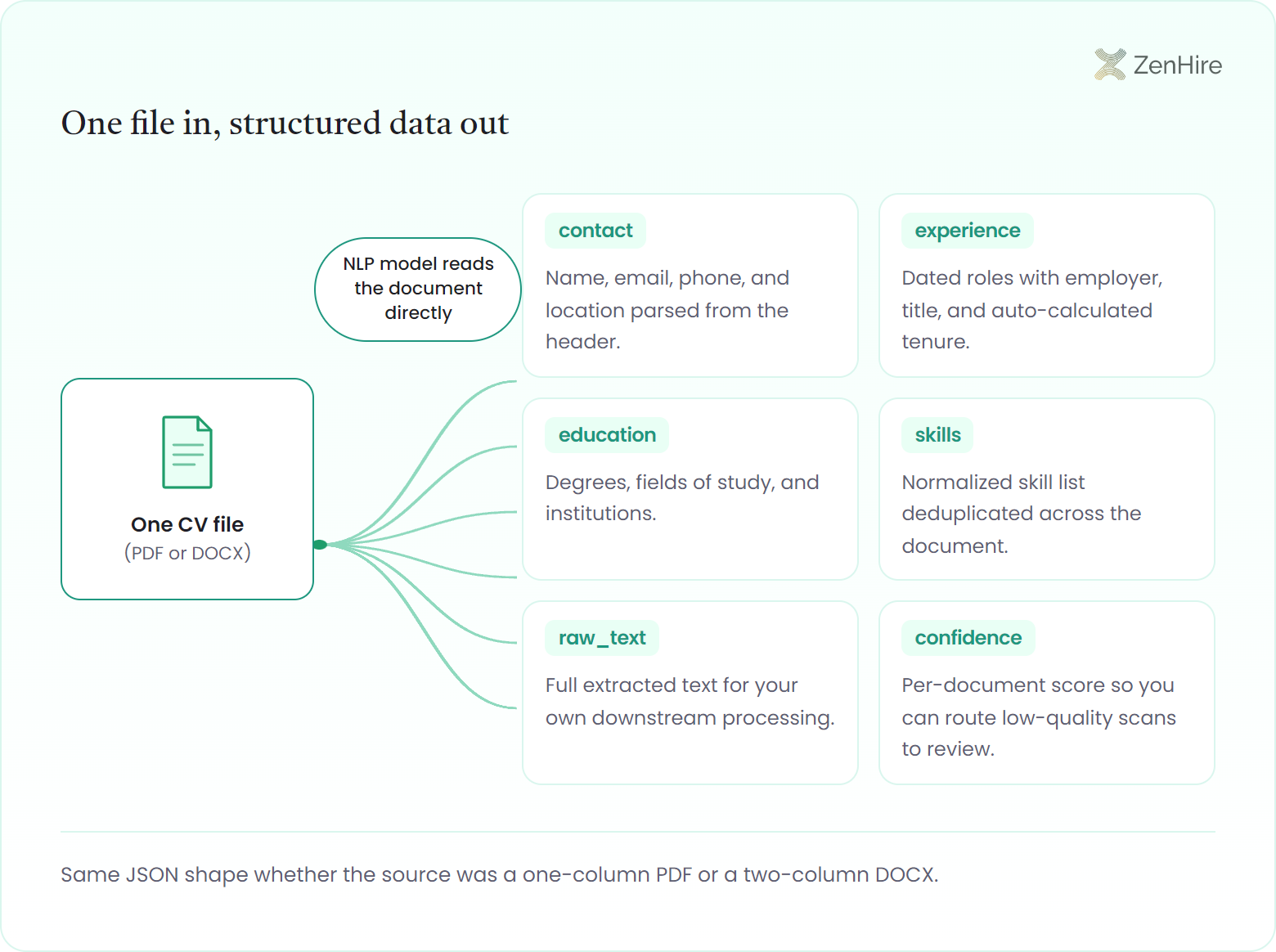
}Each call returns four structured blocks: contact details, dated work history, education, and a normalized skill list, plus a confidence value. An NLP model reads the document directly, so the same JSON shape comes back whether the source was a one-column PDF or a two-column DOCX.
Where a CV is a scanned image with no machine-readable text, the endpoint returns a low-confidence flag on the affected fields instead of inventing values, so a recruiter knows exactly which records to verify by hand. The same clean output then feeds ai cv-to-job matching without any re-keying: the parsed blocks line up with the matcher's workExperience, skills, and education dimensions, reported alongside an overall_score from 0 to 1.
Parsing quality sets the ceiling for everything built on top of it. On its own, a raw CV is a weak signal, correlating at only about r = 0.14 with later job performance; but that same document becomes the input to structured interviews and validated assessments whose combined signal clears 0.6. Garbled fields poison that chain, so extracting the contact, tenure, and skill blocks correctly is what lets each downstream stage actually add its lift.
| Field | What it carries |
|---|---|
| contact | Name, email, phone, and location parsed from the header |
| experience | Dated roles with employer, title, and auto-calculated tenure |
| education | Degrees, fields of study, and institutions |
| skills | Normalized skill list deduplicated across the document |
| raw_text | Full extracted text for your own downstream processing |
| confidence | Per-document score so you can route low-quality scans to review |
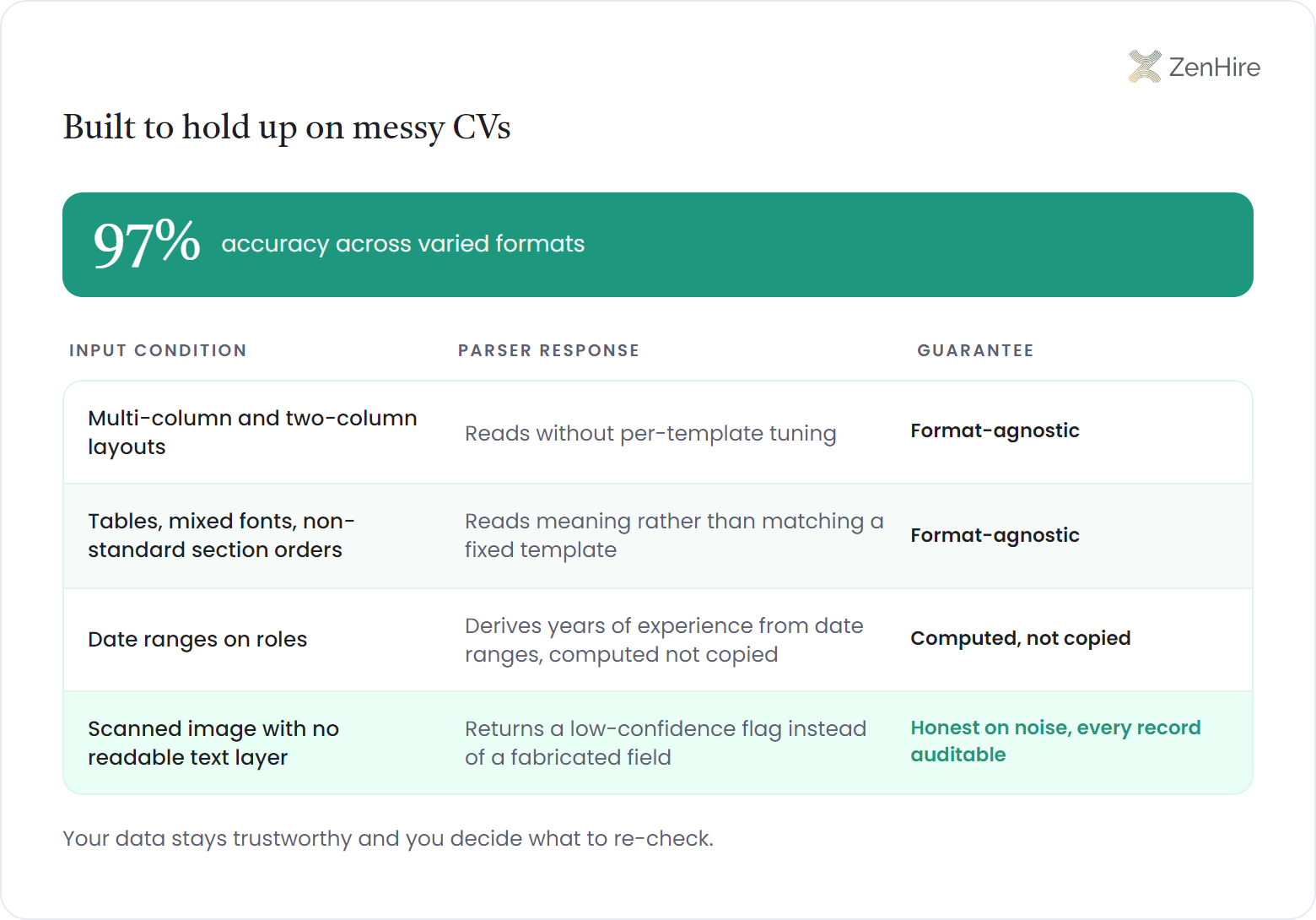
It pulls fields at 97% accuracy across multi-column layouts, tables, mixed fonts, and non-standard section orders, because the model reads meaning rather than matching a fixed template. Tenure is computed from date ranges, not copied from a label a candidate may have mistyped.
Some teams assume any parser collapses on creative or scanned resumes. This one does not pretend to: when a document has no readable text layer, it returns a low-confidence flag instead of a fabricated field, so your data stays trustworthy and you decide what to re-check, which is exactly what keeps high-volume hiring auditable at thousands of applications per role, whether that pool is a BPO applicant flood or another customer-facing surge.
You POST a file to one REST endpoint and read structured JSON back, with no model training and no template mapping. The platform ships an OpenAPI 3.1 spec and code examples in cURL, Python, Node.js, and Go, so most teams move from sandbox to production in one to two weeks, then queue bulk jobs for whole applicant pools. Teams running on an existing ATS can add this as one call in a recruitment API for their ATS rather than ripping out their system of record.
Because every record comes back in the same shape, the parsed output drops straight into a downstream candidate scoring api or your own ATS, so a backlog that took days to triage by hand clears in minutes. Each run can carry your own externalId plus up to 50 metadata keys and 20 tags, all filterable on list endpoints, and run ids never expire, so every parsed record stays traceable to its ATS-side counterpart. Teams that already parse in-house can bring that output too: CV DeepSearch ingests batches of up to 500 parsed candidates (about 10 MB) per request, with idempotent re-ingestion, and returns a best-first ranked list for each position.
One bulk job ingests 1,000+ resumes per role, and the platform is engineered to run positions with 3,000+ candidate applications without slowing down: default limits allow 500 requests per minute per client, and anything beyond 8 simultaneous processing runs queues cleanly with a 202 instead of erroring. A backlog that took a team days to read clears before the first interview is even scheduled.
1. Get a key
Sign up for an API key and sandbox, live in minutes, no sales call required. One credit balance covers every module, and failed runs are never charged.
2. Send a file
POST a PDF, DOCX, or image CV to /v1/resume-parse, one document or a bulk batch.
3. Read the JSON
Parse contact, experience, education, and skills, with a confidence value per record.
4. Route & enrich
Store the fields, flag low-confidence scans, and hand the output to the CV Matching API, which scores in a typical 1 to 3 minutes via polling or HMAC-signed, PII-free webhooks.
The resume parsing API is a REST endpoint that converts a raw CV into structured JSON. It returns contact details, dated work experience, education, and a normalized skill list, plus a per-document confidence value, from a single POST, so a PDF or DOCX becomes machine-readable data you can store, search, and score.
The cv parser api accepts PDF and DOCX resumes as well as scanned images, and reads multi-column and table-heavy layouts without per-template setup. Where a scan has no machine-readable text, it returns a low-confidence flag on those fields rather than guessing, so your data stays clean.
The resume data extraction api pulls fields at 97% accuracy across varied formats, measured against human-verified records. It computes tenure from date ranges instead of trusting a typed label, and ships a confidence value with every document so you can route uncertain scans to a quick manual check.
The resume parsing API handles bulk imports of 1,000+ resumes per role in a single job, parsing a full applicant pool before anyone opens the first file. Each call runs in milliseconds, so a backlog that took a team days clears in minutes and feeds straight into scoring.
You get an API key and a sandbox immediately on sign-up, integrate against one REST endpoint, and validate output against known CVs before going live, typically within one to two weeks. Usage is priced per call, with no per-seat fees, and the parser pairs directly with the CV Matching API.
Free for Resume Parsing API quickstart
A one-page developer spec sheet: the full JSON field map, confidence-flag handling, bulk-import limits, and a copy-paste curl call to parse your first CV in minutes.
Parse your next thousand CVs into JSON your stack can search, store, and score in one call.