How Do You Assess English Proficiency for Hiring?
· 8 min read
You assess English proficiency for hiring by scoring spoken language against the CEFR scale, not a recruiter's gut feel: a structured assessment measures hesitations, filler-word rate, vocabulary range, and words per minute. Automated spoken-English scoring aligns 90-96% with the averaged judgments of five PhD linguists, while untrained recruiters reach 68-75% and an unstructured interview predicts performance at roughly r = 0.18. ZenHire maps vocabulary, fluency, and pronunciation each to its own CEFR level (A1-C2) across 16 languages and returns a documented, auditable result in about four minutes.
Why assess English proficiency objectively for hiring?
You assess English proficiency objectively because the alternative, a recruiter's gut feel on a short call, is one of the least reliable signals in hiring. Two interviewers will rate the same candidate differently, a strong speaker can be marked down for nerves on a busy day, and nobody can later explain what "good enough English" actually meant. An objective, scored assessment removes that variance: every candidate clears the same bar, measured the same way.
The mechanism is consistency at scale. A language screen is just a selection method, and selection research is blunt about which methods work: eyeballing a resume for "fluent English" carries a predictive validity around r = 0.14, and chatting through an unstructured call only nudges that to about 0.18, while structured, scored methods stacked together clear 0.6, roughly triple the signal. Score spoken English the same way for every applicant and you inherit that reliability instead of the coin-flip. It matters most in high-volume hiring, where the pressure to fill seats invites rushed, uneven screening and the worst language mismatches slip through.
Consider a concrete example. A contact-center team hiring a hundred agents a week cannot have a senior recruiter personally judge every applicant's spoken English, so the screen gets delegated, shortened, and applied unevenly. One reviewer passes a candidate who sounds confident; another rejects an equally capable speaker who hesitated. The edge case that breaks gut-feel screening entirely is the candidate who reads and writes English flawlessly but cannot sustain a live conversation. They sail through a written test and a CV review, then fail in week two on the phones, exactly the kind of mismatch that an objective, scored assessment catches before the offer.
Objective scoring is not just more accurate, it is more accurate than people expect: in validation against the averaged judgments of five PhD linguists, an audio-based model aligned 90-96%, while non-trained human recruiters reached only 68-75%. The gut-feel phone screen is not a neutral baseline; it is the weakest link in the chain.
What do CEFR levels say about English proficiency for a role?
CEFR levels tell you, on a shared six-point scale from A1 to C2, how much English a role actually requires, so you can stop arguing about "good enough" and start matching candidates to a defined bar. The Common European Framework of Reference for Languages is the internationally recognized standard: A1 and A2 are basic users, B1 and B2 are independent users, and C1 and C2 are proficient users. The value is that everyone (recruiter, hiring manager, and client) reads the same level the same way.
The mechanism is role mapping. You decide what the job demands, set the CEFR threshold, and score every candidate against it. A customer-facing voice role usually needs B2 (can interact with a degree of fluency and spontaneity that makes regular interaction with native speakers possible), while a back-office data role might be fine at B1. A concrete example: a BPO handling inbound English support for a global client sets B2 as the floor for phone agents and B1 for chat-only roles, then routes candidates automatically by their assessed level. Read more about how this plays out in English screening for BPO and contact centers.
The edge case to plan for is the candidate who sits on a boundary: a high B1 who is nearly B2, or a candidate whose written English is C1 but whose spoken English is B1. CEFR levels are bands, not razor-thin cutoffs, so a good process flags borderline results for human review rather than auto-rejecting. That is the right division of labor: the assessment measures and ranks consistently; a person makes the call on the edge cases.
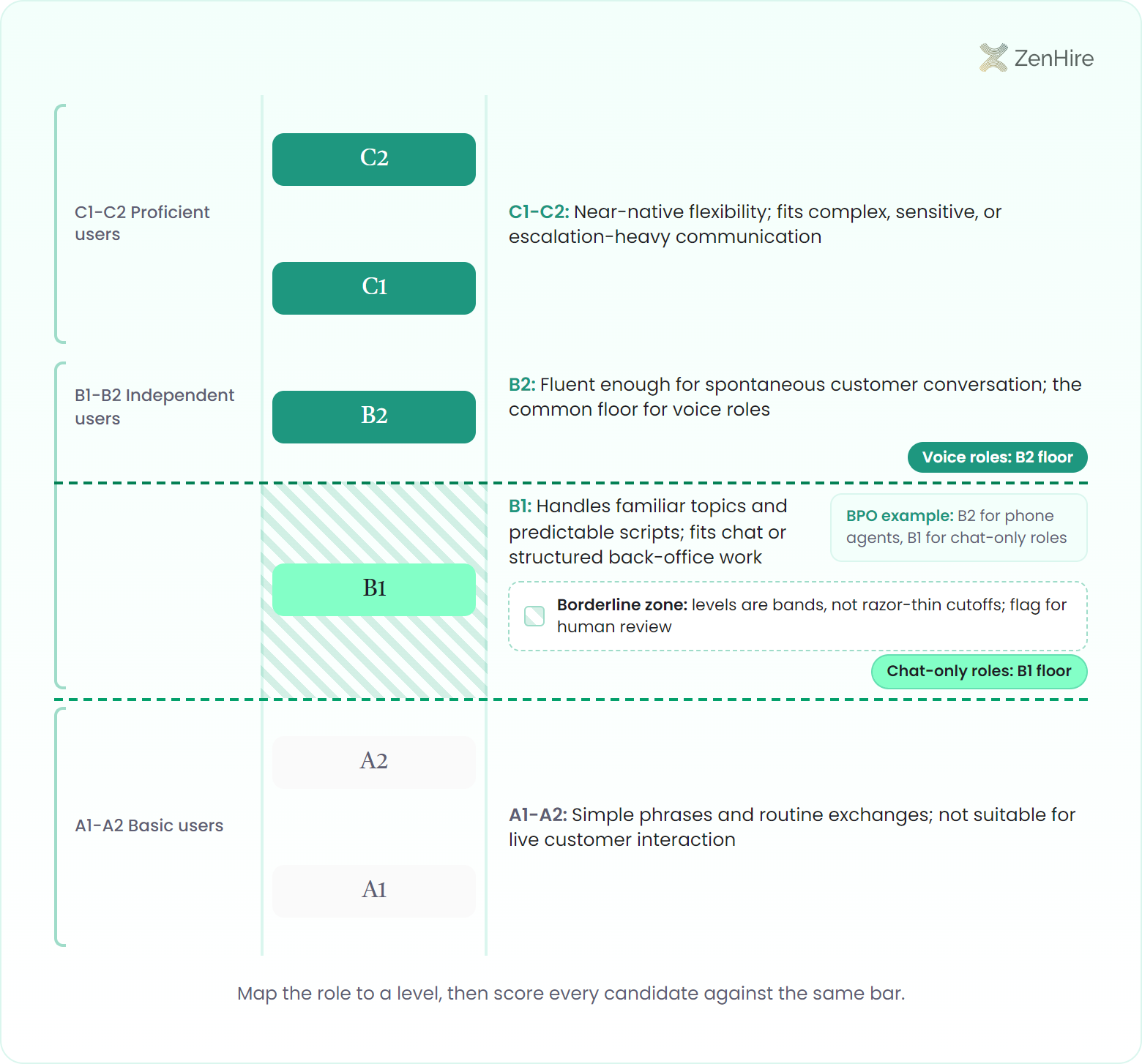
| CEFR level | What it means in practice |
|---|---|
| A1-A2 (Basic) | Simple phrases and routine exchanges; not suitable for live customer interaction |
| B1 (Independent) | Handles familiar topics and predictable scripts; fits chat or structured back-office work |
| B2 (Independent) | Fluent enough for spontaneous customer conversation; the common floor for voice roles |
| C1-C2 (Proficient) | Near-native flexibility; fits complex, sensitive, or escalation-heavy communication |
How is English proficiency scored for accent and fluency?
English proficiency is scored for fluency, not accent: a fair model measures how clearly and smoothly someone communicates and deliberately ignores how regional their accent sounds. This distinction is the whole game. Penalizing an accent is both unfair and a bad predictor, because a candidate with a strong regional accent can be perfectly clear and effective. So the scoring rewards the engineered signals of fluency and strips out the ones that leak bias.
The mechanism is a set of neutral, engineered features. Instead of a single subjective "sounds good" score, the assessment measures specific, defensible signals: non-fluent moments such as pauses and hesitations, filler-word percentage, vocabulary range, grammatical error types, and words per minute. A concrete example: two candidates with very different accents can land at the same B2 level because the model is reading their hesitation rate and vocabulary, not their pronunciation of a particular vowel. To keep it audio-only, the assessment also avoids facial or visual cues that could leak race or ethnicity, the same fairness logic behind bias-reduced hiring.
The edge case worth designing for is the gender-correlated pitch signal: a naive deep-learning model can learn to associate pitch tonality with gender and quietly penalize one group. A glass-box approach inspects and removes the neurons carrying that signal, so the score reflects fluency rather than a proxy for a protected trait. The same engine that scores speech can be exposed for live, voice-centric use through a speech assessment API, so the scoring logic stays identical whether a candidate is assessed in a four-minute interview or in a real-time call.

Fairness is built into the features, not bolted on afterward: the model scores filler-word rate, hesitations, vocabulary, grammar, and words per minute, while explicitly excluding accent patterns that penalize regional English and pitch tonality correlated with gender. Scored-response detection also flags scripted or AI-generated answers at roughly 91%, so a fluent-sounding script does not beat a genuinely fluent speaker.

When I ask a hiring team how they currently measure spoken English, the honest answer is almost always "we just know." But "we just know" is exactly where bias and inconsistency hide. I have seen a brilliant candidate rejected for an accent that had nothing to do with clarity, and a smooth-talker passed who could not actually hold a call. The fix is not to trust the machine more than the human; it is to make the machine measure the boring, neutral things consistently, then hand a person the documented result and the edge cases. That is fairer to the candidate and far easier to defend when a client asks how you scored them.
Frequently asked questions
How do you assess English proficiency for hiring?+
You assess English proficiency for hiring by scoring spoken language against an objective standard like the CEFR scale, rather than judging it on a gut feel during a phone call. A structured assessment measures fluency signals consistently for every candidate, which predicts on-the-job performance far better than an unstructured interview that lands near r = 0.18.
What are CEFR levels and how do they apply to hiring?+
CEFR levels are a six-point scale from A1 to C2 that describe English ability from basic to proficient. In hiring, you map a role to a level (B2 is a common floor for live voice roles, B1 can suit chat or back-office work), then score every candidate against that bar so the standard is identical across reviewers and clients.
Should a candidate be marked down for their accent?+
No. A fair assessment scores fluency and clarity, not accent. A strong regional accent can be perfectly clear and effective, so good scoring measures hesitations, filler words, vocabulary, and words per minute while deliberately excluding accent patterns that penalize regional English and pitch signals correlated with gender.
Why is a spoken English test better than a written one?+
A spoken test is better because most roles fail on speech, not spelling. Internal reading-and-writing tests often miss whether a candidate can sustain a live conversation under pressure, which is exactly where the on-the-job mismatch shows up. A spoken assessment screens for the skill the job actually uses.
How accurate is automated English assessment?+
Automated spoken-English scoring can align 90-96% with the averaged judgments of five PhD linguists, compared with only 68-75% for non-trained human recruiters. It also runs in about four minutes and produces a documented, auditable result you can defend in client and vendor audits.
Free for assessing english proficiency
The CEFR role-mapping cheat sheet
A one-page guide that maps common roles to CEFR levels, lists the fluency signals worth scoring, and shows which signals to exclude so accent never decides the hire.